
Learning Curve
학습 곡선은 특정 기술 또는 지식을 실제 필요한 업무와 같은 환경에서 효율적으로 사용하기 위해 드는 학습 비용을 의미하기도 하며 특정 기술을 습득할 때에 처음에는 학습 효과가 더디다가 어느 정도 이해를 하고 나면 빠르게 습득하고 후에는 다시 더뎌지는 곡선을 나타내기도 한다 - 위키백과
학습 곡선은 보통 Train set과 Validation(test) set에 대해서 각각 loss와 metric을 훈련 중간중간 마다 체크한 곡선을 말한다.
학습곡선을 사용하면 loss와 metrics의 수치를 숫자와 시각적으로 확인할 수 있으며, 모델이 underfit되는지 overfit되는지 바로 알 수 있다.

학습 곡선 사용 방법
Train set과 Validation set의 loss가 같이 충분히 떨어지는게 좋습니다. Metric으로 Accuracy 등을 사용한다면, Metric 지수도 같이 좋아지는게 바람직하다.
(1) 훈련이 잘 되고 있을 때
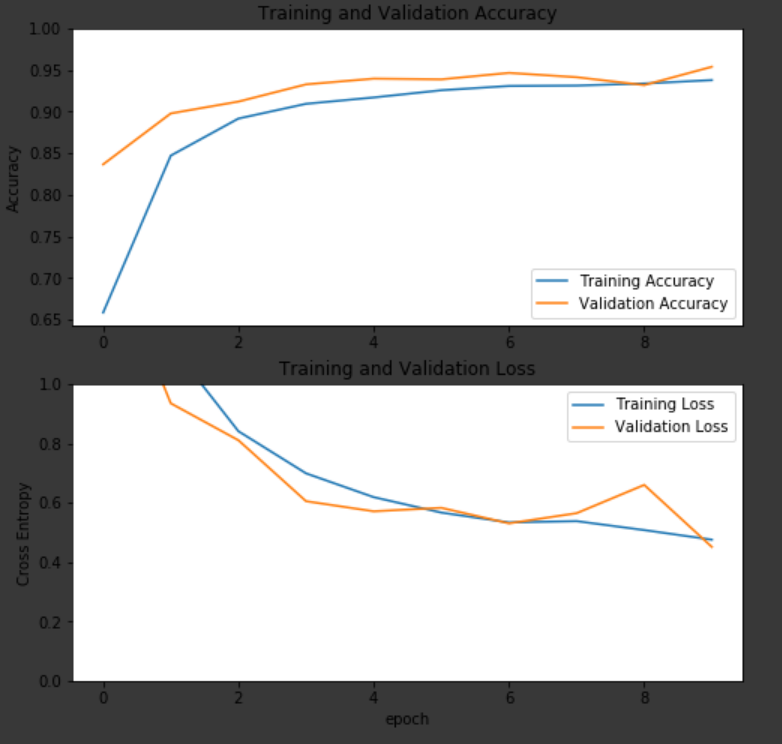
위의 사진을 보면 loss는 계속 떨어지고, Accuracy는 높아지고있는데 훈련이 잘 진행되고 있고, 언더피팅과 오버피팅이 일어나지 않는것을 알 수 있다.
위의 사진을 보면 loss가 계속 떨어지는 추세인데, 이 경우 모델이 아직 saturation이 안되었다고 말한다.
모델이 잘 만들어졌고, 데이터도 적절하다면 훈련을 지속했을때 train set loss와 validation set loss가 같이 떨어지다가, 어느 순간 validation set loss가 상승하는 경우를 볼 수 있는데 일반적으로 그 지점에서 훈련을 중단한다.
그 전에 훈련을 멈추면, 언더피팅인 상태고, 훈련을 더 계속하면 오버피팅 상태로 보며 이런 방식으로 훈련의 시간을 정하는 방식을 Early Stopping이라고도 부른다.
validation set loss가 떨어지다가 더이상 떨어지지 않고 상승하는 부분에서 멈추는 방식(early stopping)을 사용.
(2) 훈련이 잘 안되는 경우
훈련이 잘 안되는 경우에 학습곡선을 보면, loss가 애초에 떨어지지를 않는다던가, loss가 떨어졌다가 올라갔다가 떨어졌다가 요동을 친다던가 하는 여러 문제가 있다. 심지어 train loss 보다 validation loss가 계속 더 낮은 상황도 나올 수 있다.
가장 일반적인 상황
1) Train set, validation set의 loss가 둘다 안떨어질때
모델이 일단 학습을 하나도 못하고 있는 상황에 보통 딥러닝의 경우 filter수를 늘린다던가, layer를 모델의 복잡도를 더 크게 할 경우 해결됨.
2) Train set의 loss는 떨어지는데 validation set의 loss가 안 떨어질때
validation set의 loss가 하나도 안떨어지는지, 불안정한지, 일정부분 이상 안떨어지는지를 봐야 함.
일반적으로는 train set으로 훈련한 모델이, 그 외의 샘플에 대해서는 작동을 하지 않는 상황것이다.
데이터를 추가하는 방식이 가장 좋고, 그게 안된다면 모델의 일반화 성능을 좋게 해주는 방법을 찾아서 써야한다.
결국 모델의 복잡도는 적절해야 하고, 데이터는 많으면 많을수록 좋다.
이 모든 방법을 한번에 사용하면 모델의 성능은 개선 될 것이나, 자원(시간, 하드웨어 등)은 한정적이기 때문에 가장 문제가 되는 부분을 해결해야 한다. 그 외에 Train set과 Validation set이 서로 동질성을 가지는지, 둘다 전체 데이터셋을 대표할만한 데이터인지도 봐야한다.
그외에 정말 중요한 요소는 'Learning rate(학습율)' 이다. 학습율이 너무 낮거나 높으면 언더피팅, 오버피팅의 위험이 생기므로 언더피팅이 되는 것 같다면 학습율을 더 작게 하고, 오버피팅이 된다 싶으면 학습율을 더 높이는 방식을 사용한다. 그 외에 학습율을 시간에 따라서 줄이는 learning rate decay 방식 등 다양한 방법들도 존재한다.
Learning Curve를 함수로
def learning_curve(history, epoch):
# 정확도 차트
plt.figure(figsize = (10, 5)) # 차트 크기 조절을 위함
epoch_range = np.arange(1, epoch + 1)
plt.subplot(1, 2, 1)
# history는 fit 결과값을 저장하는 변수
# accuracy 차트
plt.plot( epoch_range, history.history["accuracy"])
plt.plot( epoch_range, history.history["val_accuracy"])
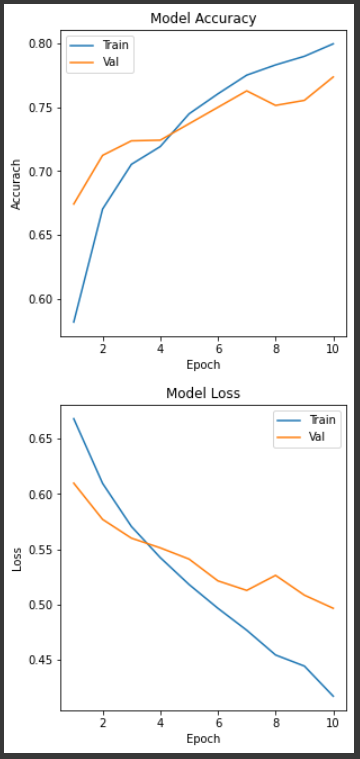
plt.title("Model Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accurach")
plt.legend( ["Train", "Val"] )
# loss 차트
plt.figure(figsize = (10, 5))
plt.subplot(1, 2, 2)
plt.plot( epoch_range, history.history["loss"])
plt.plot( epoch_range, history.history["val_loss"])
plt.title("Model Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend( ["Train", "Val"] )
plt.show()learning_curve(history, 10)
https://dataplay.tistory.com/32 [데이터 놀이터]
12. Learning Curve (학습 곡선)
1. 학습 곡선 본인이 직접 모델을 만든다던가, 논문을 구현하던가, 이미 있는 모델을 조금 바꿔서 훈련시킨다던가 할때 학습 곡선을 보는것은 굉장히 유용합니다. 학습 곡선은 보통 Train set과 Va
dataplay.tistory.com
Learning Curve를 함수를 제외한 모든 정보를 데이터 놀이터에서 가져왔다.
나같은 뉴비가 코딩 공부를 하기 좋은 블로그를 찾아 기분이 좋다.
'Tensorflow' 카테고리의 다른 글
| 판다스 Date Time Index #일자 / 시간 데이터 처리법 (0) | 2021.03.04 |
|---|---|
| 타임시리즈 데이터 분석을 위한 Prophet (0) | 2021.03.04 |
| 이미지 데이터 제너레이터가 하는 역할과 코드 (0) | 2021.03.03 |
| callback 함수 (0) | 2021.03.02 |
| 딥러닝 Keras에서 loss함수의 종류와 선택 방법 및 코드 (0) | 2021.03.02 |