
반응형
Linear_Regression은 분포된 값들 사이에서 y = ax + b인 1차 방정식을 구하여 입력 값에 따른 예측값을 산출 것이 목적이다.
여기서 x는 연차, y는 연봉으로 값이 주어지고,Linear_Regression
을 통해 찾아야 하는 것이 계수 a와 상수 b이다.
sum(실제y값 - 예측값)^2 이 최소가 되게 만드는 것을 학습이라고 한다
Linear_Regression을 통해 연차에 따른 연봉을 예측하도록 해보겠다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('Salary_Data.csv')
df.head() #데이터 프레임의 앞부분을 확인한다.
df.isna().sum() #Nan데이터가 있는지 확인한다.
X = df.iloc[:,0]
y = df['Salary']
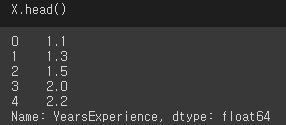
X.head()
y.head()

from sklearn.model_selection import train_test_split
#학습을 위해 테스트와 트레이닝셋을 나눈다.
X_train, X_test, y_train, y_test =train_test_split(X,y, test_size = 0.2, random_state = 5)
# training set은 80%, test set은 20%의 비율로 생성.from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
#training set을 regressor를 통해 학습시킨다.
X_train=X_train.values
X_train
X_train = X_train.reshape(-1,1) # 학습을 위해 2차원으로 변경
X_train
#### 학습 시 사용하는 함수 fit
regressor.fit(X_train,y_train)# 학습시킨 regressor에 test set을 넣어 실제값과 예측값의 차이를 확인한다.
X_test = X_test.values.reshape(-1,1)
y_pred = regressor.predict(X_test)
y_test
y_test = y_test.values
y_test - y_pred # 시각화 하기
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_test, y_pred, color = 'blue')
plt.show()
반응형
'머신러닝' 카테고리의 다른 글
| SVM - Support Vector Machine (0) | 2021.04.01 |
|---|---|
| K-NN (0) | 2021.04.01 |
| Logistic Regression의 개념과 구매 여부 분류 하기 (0) | 2021.03.29 |
| Multiple_Linear_Regression으로 회사의 이익 예측하기 (0) | 2021.03.28 |