
반응형
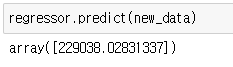
캘리포니아에 있는 회사 중 연구개발비는 210,000달러, 운영비는 170,000달러, 마케팅비는 500,000달러를 쓰는 회사가 있다. 이 회사는 얼마의 수익을 낼 것인지 예측해보자.
R&D Spend / Administration / Marketing Spend / State Profit의 다수의 컬럼들을 가진 데이터를 Multiple_Linear_Regression을 이용해 수익을 예측하는 머신러닝 모델으로 만들겠습니다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
df = pd.read_csv('50_Startups.csv.txt')
df.head() # df의 데이터 확인
X = df.iloc[:,0:3+1]
y = df['Profit']
X.head()
y.head()
# state컬럼의 데이터를 확인하여 one-hot encoding 시행
df['State'].unique()
ct = ColumnTransformer([('encoder', OneHotEncoder(),[3])], remainder= 'passthrough')
X = ct.fit_transform(X)
#학습을 위해 train_set, test_set으로 나눔
X_train, X_test, y_train, y_test =train_test_split(X,y, test_size=0.2, random_state = 7)
regressor = LinearRegression()
regressor.fit(X_train,y_train) # 학습
y_pred = regressor.predict(X_test) # 예측
y_test=y_test.values
((y_test - y_pred)**2).mean() ## MSE로 모델의 품질 성능을 확인
#캘리포니아에 있는 회사중
#연구개발비는 210,000달러, 운영비는 170,000달러, 마케팅비는 500,000달러를 쓰는
#회사는 얼마의 수익을 낼 것인가?
new_data = np.array([1,0,0 , 210000,170000,500000 ]).reshape(1,-1)
#state 컬럼을 one-hot encoding 했기 때문에 캘리포니아는 [1,0,0]을 입력한다.
regressor.predict(new_data)결과값은?
반응형
'머신러닝' 카테고리의 다른 글
| SVM - Support Vector Machine (0) | 2021.04.01 |
|---|---|
| K-NN (0) | 2021.04.01 |
| Logistic Regression의 개념과 구매 여부 분류 하기 (0) | 2021.03.29 |
| Linear_Regression (0) | 2021.03.26 |