
www.data.go.kr/data/15060369/fileData.do
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
먼저, 공공 데이터 포털에서 자료를 다운로드 받는다.
자료는 인천 1호선 19년도 일별 승하차 현황이다.

라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
오늘은 코랩이 아닌 아나콘다의 jupyter notebook에서 코딩을 했다.
matplotlib.pyplot에서 한글 사용을 위한 라이르러리 임포트
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')
csv 파일 pandas로 import.
1000단위마다 ,가 들어있으면 object형태로 인식하기에 thousands=','사용
한글처리를 위해 encoding='cp949' 사용
subway = pd.read_csv('subway.csv',encoding='cp949', thousands=',')
#자료확인
subway.head()
index를 일자로 변경해 준다.
subway=subway.set_index('일자')
subway 데이터 프래임의 컬럼 type확인
subway.info()
마찬가지로 subway에 NaN 데이터가 있는지 확인
subway.isna().sum()
연간 시간대 별 합계만 추출하여 slot_data로 변수 선언
slot_data = subway.iloc[:,2:].sum()
pie plot으로 확인
plt.figure(figsize=(10,10))
explode = (0, 0, 0, 0.1 ,0, 0, 0, 0,0, 0, 0, 0,0, 0, 0, 0,0, 0, 0, 0,0, 0, 0, 0)
plt.pie(slot_data, labels = slot_data.index ,explode = explode , autopct='%1.1f%%', startangle = 90, counterclock = False)
plt.legend(slot_data,
loc="best",
title ="시간대 별 이용객 수")
plt.show()
plot 차트로도 확인해보기
plt.figure(figsize = (12,7))
plt.plot(slot_data, '.-')
plt.title('시간대 별 총 이용 승객수')
plt.xlabel('시간대')
plt.ylabel('승객 수')
plt.show()
이제 승차 승객, 하차 승객 별 데이터를 확인해보겠다.
승차 승객 데이터
ride_subway=subway.loc[subway['구분']=='승차']
ride_subway=ride_subway.drop(['구분','계'], axis=1)
ride_subway.head()
ride_subway=ride_subway.sum()plt.figure(figsize = (12,7))
plt.plot(ride_subway, '.-')
plt.title('시간대 별 승차 승객 수')
plt.xlabel('시간대')
plt.ylabel('승객 수')
plt.show()
하차 승객 데이터
takeoff_subway=subway.loc[subway['구분']=='하차']
takeoff_subway=takeoff_subway.drop(['구분','계'], axis=1)
takeoff_subway= takeoff_subway.sum()plt.figure(figsize = (12,7))
plt.plot(takeoff_subway, '.-')
plt.title('시간대 별 하차 승객 수')
plt.xlabel('시간대')
plt.ylabel('승객 수')
plt.show()

승차 승객과 하차 승객의 수를 비교 해 보기 위해 한번 더 시각화 하겠다.
plt.figure(figsize = (12,7))
plt.plot(ride_subway, '.-', label='승차객 수')
plt.plot(takeoff_subway, '.-', label='하차객 수')
plt.title('시간대 별 승차 및 하차 승객 수')
plt.xlabel('시간대')
plt.ylabel('승객 수')
plt.legend()
plt.show()

============================================================================
다 만들고나서 저녁먹고 산책까지 갔다와서 생각이 났다.
일자별 데이터이고, 숫자데이터가 있으면 facebook의 prophet을 사용해서 미래를 예측할 수 있으니까 지하철의 수요를 예측 할 수 있다.
참고로 주피터 노트북에서는 잘 안되는거같아서 코랩으로 옮겨서 코딩했다.
pip install fbprophet
pip install plotly먼저 라이브러리를 설치해 준다.
처음에 plotly를 설치안하고 진행했는데 설치하라고 메세지가 나온다.
fb_subway = subway.reset_index()
fb_subway['일자']=pd.to_datetime(fb_subway['일자'])
fb_subway.info()프로펫을 사용하기 위해서는 '일자'컬럼의 데이터가 datetime 타입이어야 한다.

fb_subway의 데이터프레임을 살펴보자.

1년치 데이터임에도 승차와 하차로 나뉘어 730개의 행으로 이루어져 있다.
fb_ride_subway=fb_subway.loc[fb_subway['구분']=='승차']
fb_takeoff_subway=fb_subway.loc[fb_subway['구분']=='하차']
ride = fb_ride_subway.iloc[:,[0,2]].set_index('일자')
takeoff = fb_takeoff_subway.iloc[:,[0,2]].set_index('일자')
total = ride +takeoff
total=total.reset_index()먼저 승차와 하차로 데이터를 나누었고, 필요한 컬럼(['일자', '계'])만 추렸다. 사실.. 순서가 반대였다면 코드 한 줄은 덜쳐도 되지 않았을까..라고 뒤늦게 생각이 나네..?
그러고나서 '일자'컬럼을 인덱스로 설정하고 두 데이터 프레임의 숫자를 더해줬다.
그리고 다시 리셋 인덱스~

from fbprophet import Prophet
total = total.rename(columns={'일자':'ds', '계':'y'})
total
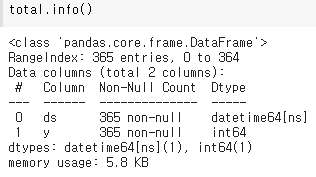
total.info()
total.isna().sum()프로펫 라이브러리를 import해주고 일자 컬럼을 ds로, 계 컬럼을 y로 이름을 변경 해주었다.
프로펫을 쓰려면 변경해야한다.
각 자료를 다시 확인했다.


m = Prophet()
m.fit(total)
future=m.make_future_dataframe(periods=365)
forecast=m.predict(future)
forecast프로펫을 통해 학습시키고 365일치의 예측을 진행한다.
예측을 하게되면 다양한 자료들이 나오게 되는데 yhat의 값이 제일 중요하다.
yhat은 y^값이며, 예측값이다.
m.plot(forecast, xlabel= 'Date', ylabel='passengers')
plt.show()
19년 자료이기 때문에 20년 12월 이후까지의 승객 수 추이를 예측한 표다.
티나게 보이지는 않지만 미세하게 우상향하고있다.
m.plot_components(forecast)
plt.show()
요건 어떤식으로 흘러갈지 trand 자료이고, 주별 자료를 보면 주말에는 완전히 저조한 모습을 볼 수 있다.
참고 사이트
matplotlib.org/stable/gallery/index.html
Gallery — Matplotlib 3.4.1 documentation
Gallery This gallery contains examples of the many things you can do with Matplotlib. Click on any image to see the full image and source code. For longer tutorials, see our tutorials page. You can also find external resources and a FAQ in our user guide.
matplotlib.org
'미니프로젝트' 카테고리의 다른 글
| SVM을 통해 구매 가능성이 있는 고객 분류하기 (0) | 2021.04.01 |
|---|---|
| 공항 기상 시각화 (0) | 2021.04.01 |
| K-NN을 통해 구매 가능성이 있는 고객 분류하기 (0) | 2021.04.01 |
| stramlit으로 크롤링을 통한 기사제목 워드클라우드 시각화하기 (0) | 2021.03.24 |
| 기사 제목 크롤링을 통한 워드클라우드 시각화하기 [완료] (3) | 2021.03.21 |